Sizing a HyperScale Reference Architecture (R.A) designed specifically for data protection, translates to a decision on number and capacity of HDD’s to be used at the server node level. This is because compute and network resources are predetermined to deliver required level of performance. The choice of server node is to be based on current disk capacity needs while also providing for future growth.
Following is a platform sizing table with total usable space(TiB) for varying block sizes, HDD counts and capacities.
Note
This table is only a representation of the various combinations and approximate backend capacities (TiB) possible on HyperScale R.A servers with 4 to 24 disks (HDD’s). It does not provide a comprehensive view of the scaling capability of HyperScale software or disks supported on a particular server.
|
HDD Count |
HDD Drive Size (TB) |
3-Node Usable (TiB) |
6-Node Usable (TiB) |
|---|---|---|---|
|
4 |
4 |
29 |
58 |
|
4 |
6 |
43 |
86 |
|
4 |
8 |
58 |
116 |
|
4 |
10 |
72 |
145 |
|
4 |
12 |
87 |
174 |
|
12 |
4 |
87 |
174 |
|
12 |
6 |
130 |
261 |
|
12 |
8 |
174 |
349 |
|
12 |
10 |
218 |
436 |
|
12 |
12 |
261 |
523 |
|
12 |
14 |
305 |
610 |
|
24 |
4 |
174 |
348 |
|
24 |
6 |
261 |
523 |
|
24 |
8 |
349 |
698 |
|
24 |
10 |
436 |
873 |
|
24 |
12 |
523 |
1047 |
|
24 |
14 |
610 |
1220 |
|
24 |
16 |
698 |
1396 |
Total disk capacity requirement is dependent on such customer driven data protection Service Level Agreement (SLA) criteria as frequency of backups, rate of change of data, retention period and number of data replicas. The idea is to translate customer data protection requirements into disk capacity needs. Then, information from the above sizing and resiliency tables may be used to arrive at a platform configuration that meets customer requirements.
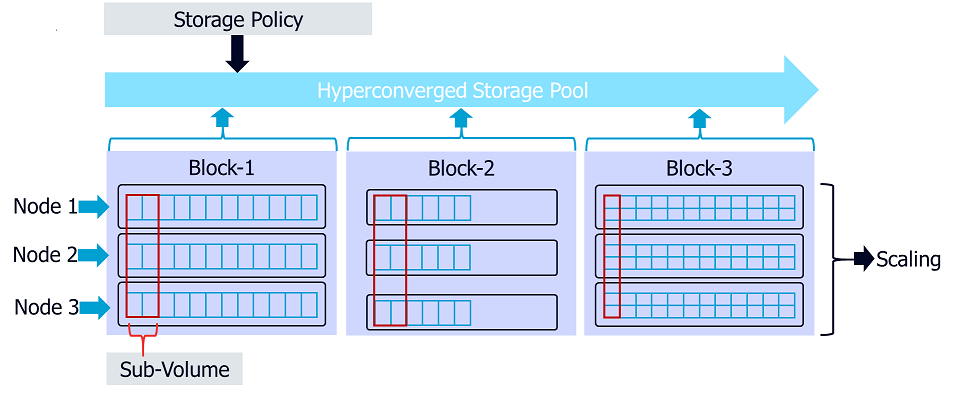
Scaling
Scaling can happen in two dimensions – "Blocks" and "sub-volumes" within each block. A Block is the number of similarly configured nodes, which presents a single volume to a client. The nodes in a block share and store erasure coded data within a sub-volume. A sub-volume is the smallest set of HDD’s (bricks) required to start and grow capacity in a block of nodes. With erasure code of (4+2), the sub-volume size is 6xHDD's. The disks in a sub-volume may be spread across either 3 or 6 nodes, depending on scaling and resiliency needs. Thus, in a 3-node block, each node will contain two HDD's from each sub-volume whereas each node in a 6-node block will have only one HDD per sub-volume. This also means we will need to scale in sets of (4 + 2 = 6) HDD's across all nodes in the block, if we are to add disk capacity to existing nodes.
New disks added as sets based on the sub-volume size are to be distributed equally among nodes in the cluster. The type and density of the HDD's within a sub-volume are to be similar to help with even distribution of data for optimal disk utilization. It is also recommended to match the disk capacity across sub-volumes for the sake of consistency in performance and to prevent inadvertent introduction of un-evenness when bad disks are replaced. Block size determines the growth factor (granularity) for adding new nodes. For example, if the original number of nodes in a block is 3, the cluster can grow by sets of 3 similarly configured nodes. All nodes in a block are to be similar in configuration. This applies to resources such as CPU, memory, SSD and HDD type, number and capacity. This is to ensure even performance and resource utilization across nodes within the block. However, a new set of nodes of the same block-size, can have a different node configuration from the previous set. The nodes are mapped to an existing CommServe for management. The addition of disk capacity through a new sub-volume or block of nodes, results in the automatic expansion of the scale-out storage pool on the CommServe.
Following is an illustration of the terms, definitions and mapping for a (4+2) erasure coded cluster with a block size of 3.
Capacity and Demand
From a business perspective, optimal resource utilization is essential for a better return on investment (ROI). Optimal utilization of IT infrastructure resources requires a matching of workloads with IT platforms they run on, and a service oriented architecture which can evolve over time to accommodate changes to workloads. This goal can be achieved only if the architecture allows for easy and fine-grained scaling of resources to meet demand. The IT resources that need to be deployed, matched, measured and scaled include compute, network and storage.
In a scale-up system, sizing happens up front, at the time of the purchase and deployment cycle. Customers have to choose between overbuying an un-balanced stack or risk running out of capacity before the next purchase cycle. Both these scenarios have huge business implications. In contrast to scale-up stacks, scale-out systems are sized minimally up front using fine grained building blocks and the organization deploys new right-sized nodes as business needs dictate. Commvault's HyperScale platform, consists of nodes with sufficient compute, network and storage resources to deliver acceptable levels of performance for the data management workload it runs. In this reference architecture (R.A), the 3 dimensions of flexibility (variables) and decisions necessary to be made are:
-
Choice of server vendor
-
Resiliency needs and
-
Server node configuration
Of these, typically vendor choice is based on customer preference tied to business and operational constraints. Resilience in Commvault's HyperScale platform, driven by system uptime requirement, is tied to erasure code and number of nodes in the cluster (block-size). Since compute and network resources are specified for the workload in question, the missing component of server node configuration is merely disk (HDD) capacity and number. Following is an illustration of the recommended configuration for compute, network and storage.
|
CPU |
20 Cores @ 2.0GHz or higher (For example, 2 x Intel® Xeon® Silver 4210R Processors) |
|---|---|
|
Memory |
256GB (For example, 8 X 32GB RDIMM) |
|
Storage |
Boot/Binaries 400GB SATA SSD (For example, 2 x 480GB SATA SSD, RAID-1) |
|
SSD Cache SSD Cache 1.6 TB/3.2TB/6.4TB Flash/NVMe/SSD (For example, 1 x 3.2TB Flash PCIe) |
|
|
Virtual Repository 4/6/12/18/24 LFF SAS/SATA (4TB, 6TB, 8TB, 10TB, 12TB, 14TB or 16TB HDD's ) (For example, 4 x 8TB, 6 x 10TB, 12 x 12TB) |
|
|
Storage Controller |
SAS HBA (pass-through mode) |
|
Network |
2 x 10/25Gbps or 4 x 10/25Gbps |
Rack servers from leading vendors conforming to or exceeding above specifications can be considered as nodes for the platform. The reference architecture approach to this scale-out platform, helps retain necessary flexibilities while also simplifying the sizing question. Further, the speed and ease of deployment and growth of a scale-out platform allows for better agility, where resources can be procured when needed and deployed just in time to cater to demand. Server vendors currently supported include Cisco, HPE, Dell and SuperMicro. Leading 2RU and 4RU server models from these vendors with raw disk capacity up to 288TB per node are within scope at present.