Introduction
The Commvault ContinuousDataReplicator Agent captures data changes continuously and stores them at a separate storage location, allowing for a faster recovery to any desired point in time. However, the benefits of the ContinuousDataReplicator Agent can be offset by redundant data as they consume considerable storage and bandwidth resources.
Therefore, choosing a deduplication-enabled ContinuousDataReplicator Agent solution for your organization will result in better network bandwidth utilization and help leverage the existing network infrastructure for cost savings.
Audience
This white paper is intended for IT architects, DR solution designers, system integrators, administrators, and others who are interested in deduplication implementation for CDP-based data protection solutions. You should be familiar with Commvault MediaAgent replication or disk library replication (SDR), discrete data replication (DDR), and journaling concepts.
Architecture
Figure 1. High-level algorithm flowchart
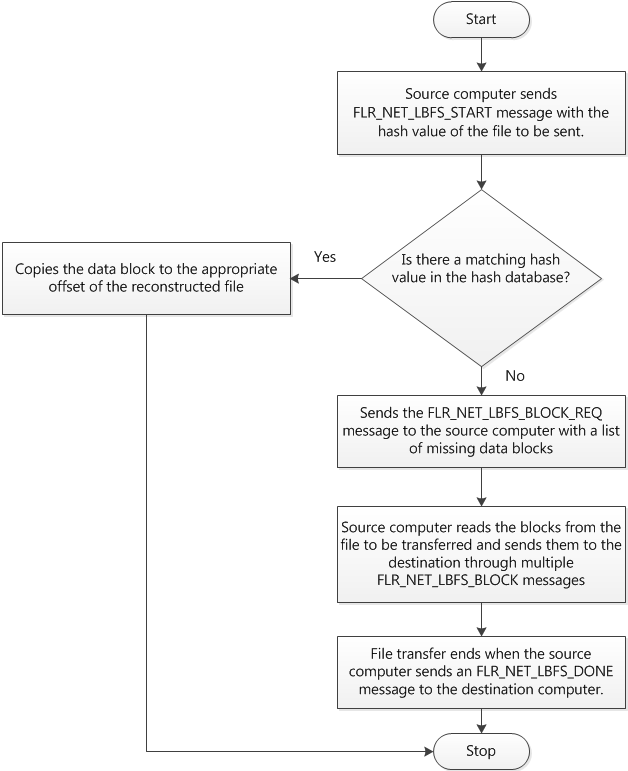
Deduplication for ContinuousDataReplicator Agent
Problem
Transferring redundant data during data replication operations of the Commvault ContinuousDataReplicator Agent data can significantly affect network bandwidth usage.
The following tables compare the data transfer performance metrics of the ContinuousDataReplicator Agent with and without deduplication. Deduplication savings are used to compare the nondeduplication-enabled solution with equivalent deduplication enabled solution.
Table 1. Performance metrics without deduplication
|
Dataset1 |
Dataset2 |
|
|---|---|---|
|
Actual data size |
~16 GB |
~17 GB |
|
Number of files |
10595 |
11620 |
|
Data transferred over the network |
16.22 GB |
17.34 GB |
|
Deduplication savings |
N/A |
N/A |
|
Time taken |
4 hour 24 min 48 sec |
4 hour 42 min |
Table 2. Performance metrics with deduplication
|
Dataset1 |
Dataset2 |
|
|---|---|---|
|
Actual data size |
~16 GB |
~17 GB |
|
Number of files |
10595 |
11620 |
|
Data transferred over the network |
13.92 GB |
6.86 GB |
|
Deduplication savings |
14.10% |
60.40% |
|
Time taken |
3 hour 55 min |
2 hour 8 min |
Solution
The Commvault ContinuousDataReplicator Agent now has a built-in data deduplication mechanism that can optimize the data transfer by excluding redundant data.
The Commvault ContinuousDataReplicator Agent also supports RSync and MD5 as alternative network optimization solutions.
In the following table, the check mark indicates the functionality that is supported by each solution.
Table 3. Comparison of network optimization solutions
|
RSync |
MD5 |
Deduplication |
|
|---|---|---|---|
|
Recommended for |
smaller-sized files |
large files |
both large and smaller-sized files |
|
Uses variable block size |
|
|
|
|
Requires a previous version of the file on the destination Note: Not useful during initial data synchronization |
|
|
|
|
To optimize data transfer, can use data blocks of all previously transferred files on a given destination |
|
||
|
Works across replication pairs, so that data transfer is optimized right from the start when you add a second pair with similar data |
|
The following table lists the deduplication solution features:
Table 4. Deduplication for ContinuousDataReplicator Agent solution features
|
Criterion for a solution |
ContinuousDataReplicator Agent feature |
|---|---|
|
What is the design approach? |
Software-based |
|
When does deduplication occur? |
Inline, with data transfer |
|
Where does deduplication occur? |
On the target server |
|
How is deduplication configured and managed? |
No configuration is required. |
|
Is data compressed? |
Yes |
Hash Algorithm
For every file to be transferred, the source computer sends a hash value of the data blocks. The destination computer looks up each of the hash values in its hash database, locates the file with the matching data block, opens the file, and re-reads and re-hashes that particular block. If its hash is still the same, it copies the block to the appropriate offset of the reconstructed file.
Data blocks for all the hashes that could not be found locally on the destination are explicitly transferred from the source to the destination.
The file transfer ends when the source sends a “done” message to the destination, at which point the destination closes the file and moves it from the reconstruction directory to the appropriate place.
Typically, you’ll have the main thread sending the “start” message, for example, for file10, while the secondary thread is still forwarding the missing blocks for file2. This means that many files will be under reconstruction on the destination at any given time.
Information about the available data blocks on the destination is stored in two databases:
-
A database containing a directory tree of all files in the file system
-
A database with the actual hashes of the data blocks.
These two databases cover all data pairs that terminate on that particular destination computer. The hash database is populated either synchronously or asynchronously.
A rehashing thread on the destination goes over all of the changed file fragments every 30 seconds and rehashes them. When a hash match is found, the file’s block is re-read and re-hashed to confirm that the file hasn’t changed since the time when it was hashed.
Note: Within the Commvault log files, message strings such as "Dedup savings: ...%" indicate the network traffic savings achieved with deduplication.
Conclusion
This paper provided information about the deduplication implementation approach for the ContinuousDataReplicator Agent. Deduplication for ContinuousDataReplicator Agent allows you to optimize existing WANs by avoiding transfer of redundant data.
The ContinuousDataReplicator Agent uses deduplication in the following data transfer use cases:
Table 5. Deduplication use cases for ContinuousDataReplicator Agent
|
Type of replication |
Use case |
|---|---|
|
MediaAgent Replication (SDR) |
Initial and incremental transfers |
|
Discrete Data Replication (DDR) |
Initial transfer |
|
DDR, without journaling |
Incremental transfers |
|
DDR, with journaling |
Incremental transfers, but only if changes to the file are substantial |
|
Continuous Data Replication (CDR) |
Initial synchronization |
|
CDR, without journaled writes |
File writes, but only if a sufficient portion of the file was overwritten |
Glossary
|
RSync |
Network optimization method for small files. |
|
MD5 |
Network optimization method for large files. |
|
SDR |
MediaAgent replication or disk library replication. |
|
DDR |
Discrete data replication. |
|
Journaling |
Mechanism to keep track of changes not yet committed to the file system. |