Commvaults scale-out data protection platform - HyperScale, requires a minimum of three servers (nodes). The nodes, each with sufficient resources of CPU, memory, storage and network, are deployed with the required software stack to create the data protection platform. As with a traditional setup consisting of Commvault MediaAgent, the nodes in HyperScale are mapped to a Windows server running the CommServe server software(UI). The CommServe server provides a consolidated view and means to manage all MediaAgents and conduct data protection activities.
The recommended node configuration is as follows:
|
CPU |
20 Cores @ 2.0GHz or higher (For example, 2 x Intel® Xeon® Silver 4210R Processors) |
|---|---|
|
Memory |
256GB (For example, 8 X 32GB RDIMM) |
|
Storage |
Boot/Binaries 400GB SATA SSD (For example, 2 x 480GB SATA SSD, RAID-1) |
|
SSD Cache SSD Cache 1.6 TB/3.2TB/6.4TB Flash/NVMe/SSD (For example, 1 x 3.2TB Flash PCIe) |
|
|
Virtual Repository 4/6/12/18/24 LFF SAS/SATA (4TB, 6TB, 8TB, 10TB, 12TB, 14TB or 16TB HDD's ) (For example, 4 x 8TB, 6 x 10TB, 12 x 12TB) |
|
|
Storage Controller |
SAS HBA (pass-through mode) |
|
Network |
2 x 10/25Gbps or 4 x 10/25Gbps |
Erasure Coding (EC) is used to protect data from hardware failures on HyperScale. Encoded and redundant data is broken into fragments and spread across storage devices to provide hardware resilience from disk and node failures. A set of similarly configured server nodes which share and store erasure coded data, constitute a "Block". Nodes within a block communicate over a private StoragePool network. Nodes across different blocks can be configured differently. Currently supported block sizes are 3, 6 or 12 nodes. The subset of disks across all nodes in a block, used to house the erasure coded chunks of data constitute a sub-volume. The following diagram depicts a sub-volume with 6 HDD’s for erasure code of (4+2). Given there are a total of 12 HDD’s per node, this translates to 6 sub-volumes in the block of nodes:
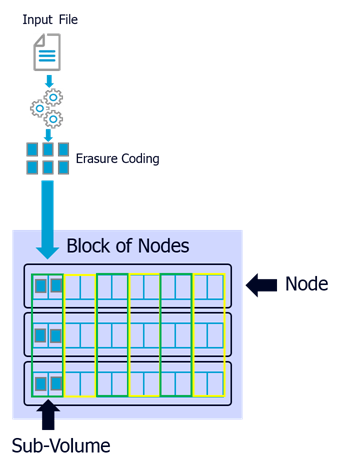
A HyperScale node can perform the role of either a "Control" node or a "Data" node. Control nodes host the deduplication database (DDB) for the storage pool and all nodes host the index cache. The 6 deduplication database (DDB) partitions are distributed equally across the available control nodes. It is recommended to have a minimum of 3 control nodes for each storage pool. The processing capability at the node level is used for all MediaAgent functionality, including erasure coding, indexing and for moving data from the client. By default, the operating system (OS), deduplication database and index cache use the SSD’s which are pre-selected as targets during the install phase. The NL-SAS capacity HDD’s contain the data to be protected. Given that hardware resiliency from disk and node failures is provided by erasure coding on JBOD, a RAID controller is not required. Individual nodes are required to have a minimum of two 10G network ports to support public data protection traffic from clients and for private StoragePool traffic between the nodes in the scale-out platform. Resiliency at the network level is provided through bonding of interfaces.
A Scale-out architecture eliminates growth related bottlenecks encountered in the scale-up model, where dedicated storage controllers limit performance and capacity. The scale-out HyperScale model achieves growth by adding compute, memory, cache and network resources with storage, through appropriately configured building-blocks (node) published as Reference Designs. This approach allows for the gradual and granular addition of performance (CPU, memory and network bandwidth) and capacity (HDD) as required. Blocks of servers from various generations, makes and models can contribute compute, network and storage resources towards a shared storage pool. Another key benefit of the scale-out HyperScale data protection platform is the ability to expand without service disruption.
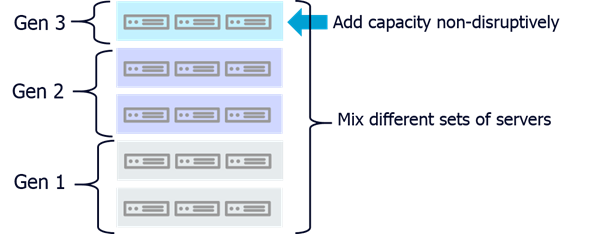
The "Block" size of similarly configured nodes has a bearing on the resiliency of the platform and cost to the customer. Resiliency of the system is also dependent on the erasure coding scheme selected. For example, following is a set of recommended block sizes for the default erasure coding scheme of (4 + 2), where an incoming block of data is split and encoded into a total of 6 smaller blocks. This scheme allows for the loss of any 2 of the 6 blocks stored without service disruption:
|
BLOCK SIZE |
RESILIENCY |
|---|---|
|
3 - Nodes |
Tolerance against failure of 2 disks per sub-volume or 1 node failure per block. |
|
6 - Nodes |
Tolerance against failure of 2 disks per sub-volume or dual node failure per block. |