Introduction
Our software platform is based on a common set of core functions or capabilities, namely, data collection, data movement, data storage, data tracking, and data analytics. All functions share the same back-end technologies to deliver the unparalleled advantages and benefits of a holistic approach to protecting, managing, and accessing data.
To understand our software, you should understand ContentStore. Every product and feature of our software is tied to ContentStore, which is the core of our software strategy, the springboard for all product development, and the overarching feature that sets our software platform apart.
What is ContentStore?
ContentStore is not a physical entity, it is a virtual repository of managed data, no matter where that data physically resides. It is the means by which passive data is turned into active content.
Data enters the ContentStore scope of influence by different methods. Once data is in ContentStore it benefits from our software's rich feature set, such as security, deduplication, analytics, and much more. From ContentStore it can be accessed both by administrators and end-users by a number of different means.
ContentStore appears to be the actual repository of data, because it is what users interact with, but the content itself can reside on premises or in the cloud. As long as it is in ContentStore, its actual, physical location doesn't matter. To understand more about ContentStore, consider these questions:
-
How does data enter the ContentStore sphere of influence?
-
What is the key feature set available for data in ContentStore?
-
What are the ways in which data in ContentStore can be accessed, using either Commvault software, or integration with native or third-party products?
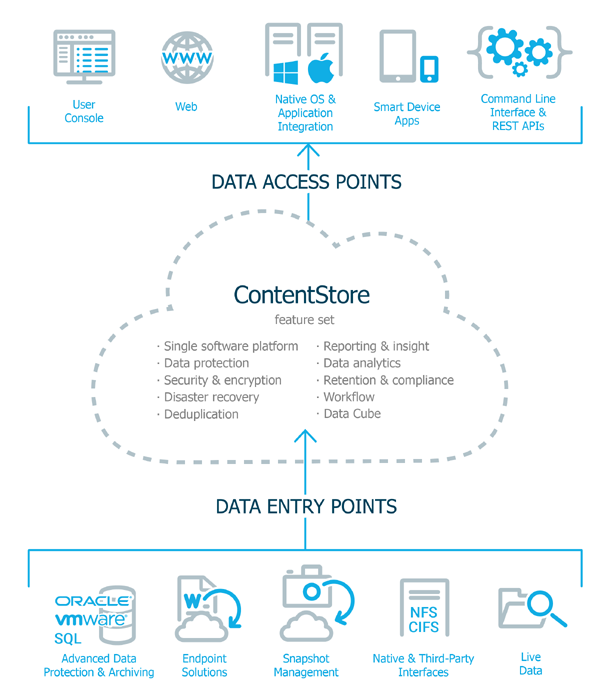
ContentStore Unifies All Managed Data
In a typical enterprise, there are many different types of data; files on desktop and laptop computers; mail and database servers; data in content management systems like SharePoint; and many more. This data is not all in one physical location. Data might be on users' computers, in the cloud, or in IT centers scattered around the globe. With such a diversity of data types and locations, different protection and recovery requirements, and environments where multiple solutions are required, you do not want to maintain a separate point solution for each requirement, so our integrated data management approach with ContentStore provides a single, complete view of all managed data no matter where that data resides.
To take advantage of the rich Commvault software feature set, data must be made available to our software, to enter the ContentStore sphere of influence. There are a number of ways in which this is accomplished.
Advanced Data Protection and Archiving
The most basic function of our software is data protection and recovery. Basic backup is the foundation of a comprehensive data protection and management strategy, and our software offers seamless and efficient backup and restore of data from any mainstream operating system, database, application, endpoint, or virtual environment with maximum efficiency according to data type and recovery profile. With a single, low-impact scan, our comprehensive backup and archiving software can incorporate the traditional backup and archiving processes in a single operation, moving data to secondary storage where the data functions as both a backup and archive copy.
Content-based retention can take advantage of ContentStore intelligence to store only the data that is valuable. With this capability, you can design and customize the data you want to retain, according to its business, compliance, or evidentiary value.
Virtualization demands a data management solution that is aware of dynamic workloads, consolidated resources, and cloud-based computing models. With our software, you can protect all of your VMs quickly and unify the data protection of both your physical and virtual environments - as data from VMs is protected in the same manner as data from physical computers, and benefits from the same rich feature set in our software. In addition, you can optimize recovery and retention of files, VMs, and virtualized applications. Policy-based auto-protection of VMs ensures that no VM will be unprotected.
For more detailed information, see:
Endpoint Solutions
Commvault Endpoint Solutions offer data protection, security, access from anywhere, and search capabilities for end users, such as laptop users, to protect against data breaches and increase productivity while providing self-service capabilities. End users have immediate access to their files, regardless of where they create them, and can securely share, search, and restore files using their own mobile, desktop and laptop devices, without assistance. Commvault Endpoint solutions provide global access to distributed files and documents without using third-party file sharing and cloud backup services, which are outside the security and control of corporate IT.
Commvault Edge Drive can be used as a dropbox, allowing data copied to the Edge Drive to be available to the user on that client or other client computers. For example, users can configure Edge Drive on a desktop computer, copy files to the Edge Drive, and those files are then accessible from their laptop, and through the Web Console. When files in the Edge Drive are edited, the changes appear on all the user's Edge Drive enabled devices. Files in Edge Drive are protected, so users can retrieve the files from Edge Drive to another location even if the original files are lost.
For more detailed information, see:
Snapshot Management
Commvault snapshot management technology integrates the complex lifecycle of snapshot management into one seamless framework. This integrated approach makes it quicker, easier, and more affordable to harness the power of multiple vendor array-based snapshots, accelerating backup and recovery of applications, systems, VMs and data. Our software automates the creation of hardware snapshot copies across a multi-vendor storage environment. Our software indexes all the files in the snapshot and adds that information to ContentStore, so that the backed up data is no longer just a snapshot or 'picture'. This means that the individual files in the snapshot can be located and recovered quickly when they are needed without the use of additional processing or recovery tools. This strategy allows you to meet both your Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO) from a single snapshot of the source.
For more detailed information, see:
Native and Third-Party Interfaces
Commvault REST APIs can be used to create custom interfaces that focus on the operations our software can perform. (Representational State Transfer, or REST, is a software architecture style for building scalable web services, and an application programming interface, or API, is a set of routines, protocols, and tools for building software applications.) The REST APIs are implemented in a way that allows them to be used with standard programming language and tools. This allows you to use features of our software from your own software, for example, performing backup and recovery operations from your own software interface. Our native interfaces also allow applications to directly send data to our ContentStore using standard network protocols (CIFS and NFS) on servers and laptops.
For more detailed information, see:
Live Data in the Enterprise
You do not have to back up your data to take advantage of our software's rich feature set. Our software can also collect information about live data from multiple sources, such as file systems, databases, web sites, and applications - making it available for our search and analytics tool. For instance, you might need to analyze large amounts of log data from multiple sources in your environment, and with our log monitoring software, you can set up policies to collect and filter such log data to efficiently analyze and monitor the state of your environment. These logs might be generated by our software, or by various servers in your environment, or manually uploaded, but they can all be monitored and analyzed by our software, and viewed from our console, based on a common set of rules defined in our software.
For more detailed information, see:
Core Software Features
Built on our core data platform is a rich feature set that uses a policy-based approach. All functions share the same back-end technologies to deliver the unparalleled advantages and benefits of a truly holistic approach to protecting, managing, and accessing data.
Additionally, our software removes any hard linkage into physical storage. All of the ContentStore services and management functions exist in a virtual construct independent of any particular hardware device. ContentStore can seamlessly migrate and move data between cloud, web, mobile, and software devices.
Collected data is transposed into content through indexing, search, reports, alerts, and monitoring. This content can be securely shared for use by a variety of users and applications.
Security and Encryption
Our software securely protects data and information - whether it's on premises, at the edge, or in the cloud. Security is baked in to the platform to secure data on desktops or laptops, in the office or on the road, at rest or in flight, utilizing efficient encryption, granular and customizable access controls for content and operations, role-based security, single sign-on, alerting, and audit trails to keep your information secure. Our security will reduce privacy breaches and exposure events, and reduce costs by efficiently securing stored data. And Single Sign-On (SSO) enables users to log on with a single set of credentials and access our secure software without managing multiple user names and passwords.
For more detailed information, see:
Disaster Recovery
Disaster recovery begins with planning and preparation for a disaster, and a set of protection procedures that are used to prepare for and recover from a disaster. Disaster Recovery types are defined by your Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO). Disaster preparedness comes in many degrees, ranging from no off-site backup data, to having a highly automated, business-integrated solution that automatically manages a complete switch of all resources from one physical site to another. Our software is configurable for any level of disaster recovery preparedness that you choose. Our software goes even further in preparing for a disaster. Using a predefined template for our Workflow engine, you can automate disaster recovery preparations, and quickly copy critical files to a remote disaster recovery site. You can easily convert physical computers to virtual machines to simplify disaster recovery, or convert virtual machines from one type to another. You can also configure our software to automatically switch to a different pathway from the computer to the data storage location when backing up data, if a component of the primary pathway fails.
For more detailed information, see:
Deduplication
The deduplication integrated into our software reduces backup times while saving on storage and network resources by identifying and eliminating duplicate blocks of data during backups. All data types from Windows, Linux, and UNIX operating systems, virtual machines, supported applications and databases, and SaaS applications are deduplicated before moving the data to disk storage, reducing the time and bandwidth required to move data by up to 90 percent, reducing the space required for storage, and reducing the time required to restore data.
For more detailed information, see:
Reporting and Insight
Access to actionable information is critical to informed decision-making and operational excellence, so our software has robust, built-in reporting analytics, with operational reporting integrated with data management operations, eliminating the need for third-party reporting tools. Global, web-based reporting provides a rich understanding of operations with deep views into data, usage and environmental characteristics, business intelligence for infrastructure cost planning, and simplified compliance audits. Live instrumentation and dashboard views provide summary and analytic views of utilization, success rates, and a host of other parameters designed to simplify data management and infrastructure, while historical operations data is available for regular status reporting, trend analysis and best practice comparison to achieve operational excellence.
For more detailed information, see:
Analytics
Analyze your data to gain insight to the underlying processes and discover meaningful patterns. Third-party applications can also access and utilize the information in our ContentStore for analytics purposes. Our software provides data analytics to view statistical information about data, web analytics to improve the usability and the content of a website or application, and data connectors to collect the information residing in various data repositories throughout the enterprise.
For more detailed information, see:
Retention and Compliance
User-defined retention policies allow you to automatically organize, classify, and store only the information that truly matters to your business - based on relevant and usable criteria, such as file name, type, content, tags and keywords - reducing the cost, complexity, and risk of storing massive volumes of data. As a result, our software reduces storage requirements, improves application performance, and helps you meet your business and compliance needs. Reduce costs by being able to rapidly respond to regulatory compliance and legal discovery requests. Civil litigation requires that data that is relevant to a case be provided for legal discovery, which can be a very time-consuming task for compliance officers. The data that they need to provide to courts or attorneys might be spread across many different computers and storage devices throughout the organization, and can be comprised of different data types. Once again, our ContentStore unifies all of this data into a single, virtual repository and indexes it for unified search across all data.
For more detailed information, see:
Business Process and Workflow Automation
Our software makes it easy to automate your routine, repetitive, or complex data management tasks by selecting from a catalog of pre-configured workflows or create your own using our intuitive graphical user interface - simplifying processes, saving time and money, and reducing the risk of human error. You can automate repetitive or complex manual operational tasks by bringing together sets of individual activities in a specific order or decision tree. The benefit is not merely the time saved, but the bullet-proof repeatability achieved by automation. Operations such as backup, restore, user registration, and even tasks unrelated to data management can be easily automated by implementing workflows. This helps ensure that your IT services are aligned with the needs of the business and can support its core processes, facilitating business change, transformation, and growth.
For more detailed information, see:
ContentStore Access
Access to configuration and data operations is provided to Administrators, and for end-users, access is provided for specific purposes, such as searching, viewing, and restoring their own protected or managed files. ContentStore removes traditional data processing boundaries and extends our software's vast array of data services and management services directly to the end user. This is done though new and ever expanding integration portals with commonly used end user devices and applications.
Access Methods
-
Command Center: A web-based user interface for administration tasks that provides default configuration values and streamlined procedures for routine data protection and recovery tasks and access to ContentStore.
-
CommCell Console: A central management interface for managing operations, monitoring and controlling active jobs, viewing events related to all activities, and accessing the ContentStore.
-
Web Console: A browser-based application that allows end-users to perform data management operations such as backup and restore, run reports, download software packages, and manage virtual machines.
-
Native OS and application integration: Native plug-ins for Windows Explorer, Microsoft Outlook and IBM Notes that allow users to browse and retrieve files from ContentStore.
-
Command Line Interface and REST API: You can perform backup, restore and other operations from the command line, and run these operations individually from the command prompt or combine these operations into a script or third-party application for automation. REST APIs can be used to create custom interfaces that focus on the access to ContentStore that users need.
-
Industry standard protocols like NFS, CIFS, HL7, DICOM, XDS, iSCSI: Support for these industry standards allows applications and users to easily access data within ContentStore
Access to Live Data
Our software is not just about backed up data, but encompasses live data in the enterprise as well. You can browse the files on your work computer from your iPhone, or from a web browser on a remote computer. In addition, VPN for Endpoint Access is integrated in our software - specifically because it provides a seamless experience when you need to access live data from a remote location.
Conclusion
Our software products, features, and solution are not merely loosely coupled; they are all tied to ContentStore. They are certainly diverse, to meet the demands of very diverse workloads, infrastructures, and applications - from snapshots to streaming. With all that diversity, the last thing you need is to maintain a separate point solution for each distinct requirement. With our software, you don't have to. Our integrated approach gives you a single, complete view of all your data no matter where that data actually resides.