In general, the data aging process compares the retention settings on the storage policy copy to the jobs on the disk. Any jobs that are eligible to be aged will have their associated data chunks marked as aged. For deduplicated data, the data blocks within the data chunks are referenced by multiple jobs. Therefore, the pruning process for deduplicated data checks the DDB to determine if the block is being referenced by multiple jobs. If the block is referenced by other jobs not yet eligible for pruning then those blocks will be maintained on the disk. This means that for deduplication, the data is not deleted from the disk at the data chunk level but instead at the data block level.
Note
-
If a DDB is marked as offline, the DDB will not be aged until all data on the DDB is eligible for aging.
-
Do not manually delete the DDB content. The DDB facilitates the deduplication backup jobs and data aging jobs. If deleted, new deduplicated backup jobs cannot be performed and the existing data in the disk mount paths will never be aged.
-
For deduplication enabled storage policy copy, we recommend not to configure extended retention rules because the jobs with extended retention rule can hold on to the unique data blocks that gets aged by the basic retention rule. This is because, for deduplication, the data is written in the form of unique data blocks and these blocks are shared among multiple jobs.
-
As a result, when the basic retention jobs are aged, very little space gets reclaimed from the disk library. The actual space gets reclaimed back from disk library only when the extended retention jobs are aged.
-
If you still want to configure extended retention rules for deduplicated jobs, we recommend you to create a selective copy with deduplication for each selective criteria (for example, weekly, monthly, and so on) and set the higher basic retention period on each selective copy. See Creating a Selective Copy for instructions.
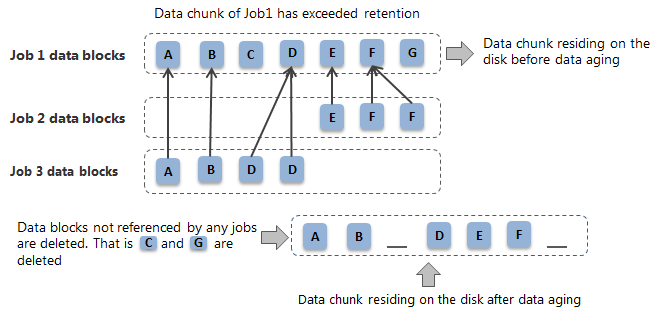
For example, in the following diagram 3 jobs (Job1, Job2, and Job3) are retained in the storage.
-
Job1 has exceeded retention.
-
Job2 and Job3 has referenced blocks from a data chunk belonging to Job1.
When data aging job runs, it will determine if the data blocks from the data chunk are being referenced from other jobs. In this case data block C and G will no longer be referred when Job1 is aged and those data blocks will be deleted. All other data blocks will remain in the disk.
Optimized Pruning of Deduplicated Data
You can configure the following additional settings to set the number of pruner threads to optimally prune the deduplicated data from the disk and the cloud library.
Note
Setting higher number of pruner threads will increase the I/O on the mount path.
Procedure
For disk library:
-
To the MediaAgent, add the DedupPrunerThreadPoolSizeDisk additional setting as shown in the following table.
For instructions on adding the additional setting from the CommCell Console, see Adding or Modifying Additional Settings from the CommCell Console.
|
Property |
Value |
|
Name |
|
|
Minimum Value |
0 |
|
Maximum Value |
20 |
|
Type |
Integer |
For cloud library:
-
To the MediaAgent, add the DedupPrunerThreadPoolSizeCloud additional setting as shown in the following table.
For instructions on adding the additional setting from the CommCell Console, see Adding or Modifying Additional Settings from the CommCell Console.
|
Property |
Value |
|
Name |
|
|
Minimum Value |
0 |
|
Maximum Value |
20 |
|
Type |
Integer |